
Protocol Buffers 编译器源码阅读
前言
Protocol Buffers (简称 pb/protobuf) 是谷歌公司开发的一款跨平台跨语言的结构数据序列化框架,可以使用 protobuf 的提供的编译器将定义好的数据模型( proto文件 )编译为各种语言,提供对应的特殊数据结构的序列化、反序列化能力。protobuf 性能好,语法简洁,广泛应用于 rpc 框架中,为其提供编解码的能力。
除此之外,protobuf 还是一个优秀的 C++ 开源项目 Github,在社区里询问阅读什么项目提升自己的 C++ 编码能力时,也有很多人推荐阅读 protobuf 的源码。
出于工作上的原因,最近我也对 protobuf 的编译器源码(Protocol buffers 3)进行一定阅读,发现它的代码整洁,逻辑清晰,设计也非常好。因此写一篇这样的文章记录一下阅读的一些收获。
编译器相关知识
如果完全没有编译器相关的知识,那么阅读 protobuf 的源码是无从下手的。和寻常的编译器一样,protobuf 也可以分为编译器前端和后端,并完成了一个从源语言到目标语言的转换。对于传统编程语言来说,即是从源代码到机器直接执行的机器码的转换。
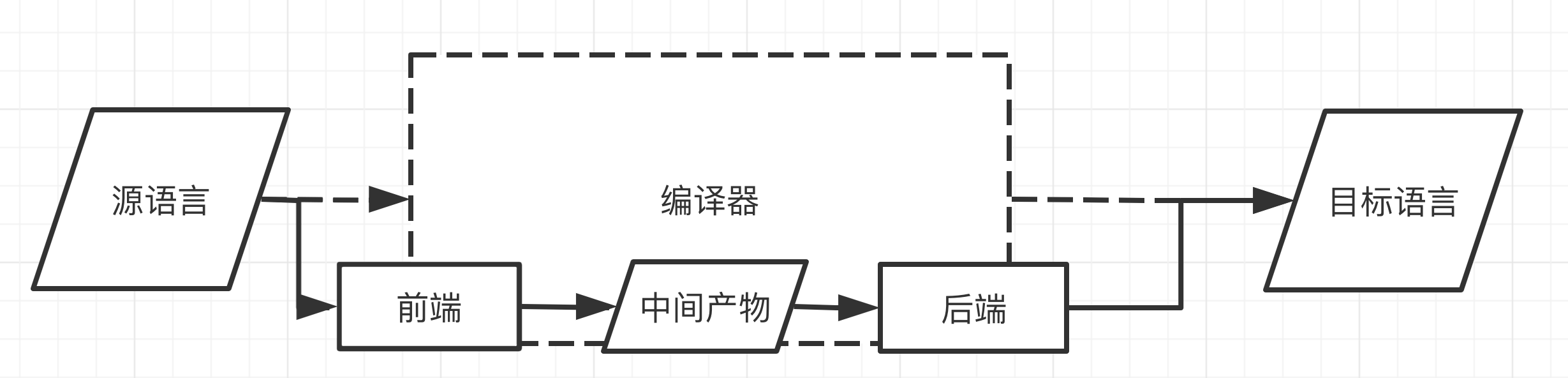
如图所示,对于 protobuf 来说,源语言就是一个 proto 文件,定义了数据结构。而目标语言则是对应语言的源代码。以便于各种语言直接调用使用。
目前 protobuf 支持的语言如下。也就是说,定义好的 proto 文件会转换为下列语言的源代码。
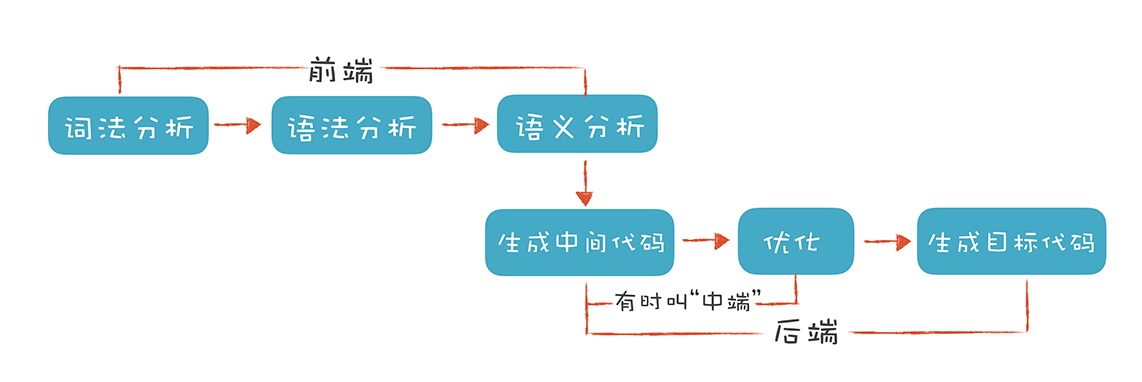
对于编译器来说,前端主要完成的工作是词法分析,语法分析,语义分析。
假设我们已经完成了预编译器的工作(一般包括去除空格,插入头文件,展开宏等等……事实上,根据不同的语言复杂程度,预编译器的工作也可能会非常复杂)。假设我们的语言非常简单,不需要引入什么头文件,展开宏等等,那么输入的目标语言将会被去除多余的空格和换行符。
这样,对于编译器来说,目标语言只是一串连续的字母和特殊符号的序列,比如:
|
|
单个字母和符号一般不能表达什么含义,因此 词法分析 是将单词组合拆分成 token(单词)的形式, 如上述代码中的 while 和 true。经过词法分析,字母和特殊符号的序列就转化为了一串由单词形式组成的序列。
而 语法分析 则是将这个单词的序列组织成一个抽象语法树(Abstract Syntax Tree,AST),后文会针对protobuf使用的语法分析方式介绍这一过程的实例。
至此为止,其实编译器也只是将源语言,从一种不包含结构的序列形式转换成了含有结构的形式。这其中产生了任何的理解了吗?没有,至此位置,计算机只是对数据进行了一些处理工作,但并不知道我们的代码做了什么事情。
但是组织一棵树的形式,则为语言初步理解源代码做了什么,做的事情是否合法提供了条件。编译器会反复阅读这棵树,根据这棵树的结构来分析语义,来判断程序员输入的东西是否合理。在这个过程中,编译器会为AST的每个节点填写一些属性。这就是 语义分析。