
从 0 开始学习 Transformer 下篇:Transformer 训练与评估
1. 前言
在上一篇文章中我们已经描述了 Transformer 的整个模型搭建过程,并逐层逐行地解释了其正向传播的原理和细节。接下来,我们将着手定义优化训练的方式,处理语料,并最终使用搭建好的 Transformer 实现一个由葡萄牙语翻译至英语的翻译器。
为了训练一个由葡萄牙语翻译至英语的翻译器,首先来观察如何处理数据从而能够正确地输入我们已经设计好的 Tranformer 模型:
|
|
只摘取模型的调用 call 部分,可以看出 Transformer 需要的输入:
inp:输入序列,这里需要的是源语言(葡萄牙语)的编码表示。(嵌入表示将在编码器中完成)tar:目标序列,这里需要的是目标语言(英语)的编码表示。(嵌入表示将在编码器中完成)training:布尔量,规定模型是否可以训练。enc_padding_mask:编码器,填充遮挡。look_ahead_mask:前瞻遮挡。两个遮挡将在后面详细描述。dec_padding_mask:解码器,填充遮挡。
由此,我们知道,为了达成目的,我们需要完成以下几个步骤:
- 创造原训练集(输入句子和目标句子)的嵌入表示
- 为我们的 Transformer 设计优化器和损失函数
- 根据情况创造填充遮挡
- 为了实现自回归创建前瞻遮挡
- 将数据输入进行训练
- 最终对训练好的模型进行评估
2. 创造原训练集的编码表示
2.1. 数据下载与读取
参考 Tensorflow 的官方教程,我们同样使用 TFDS 来进行数据的下载和载入。(应首先在本机环境或虚拟环境中安装 tensorflow_datasets 模块。
|
|
第一行代码会访问用户目录下(Windows和Unix系系统各有不同,请参考官方文档)是否已经下载好了葡萄牙翻译至英文翻译器所需的数据集,如果不存在,则会自动下载。第二行,则将其自动转换为训练集合和测试集合两个 tf.data.Dataset 实例。
2.2. 创建子词分词器
tfds 独立于 Tensorflow,是专门用来管理和下载一些成熟的数据集的Python库。但其中有很多我认为通用性很强的函数。比如子词分词器:
|
|
上方代码分别创建了两个子词分词器,分别读取了训练集合中的全部英文和葡萄牙文,并基于这些大段的文字形成了子词分词器。
子词分词器的作用是将输入句子中的每一个单词编码为一个独一无二的数字,如果出现了子词分词器不能识别的新单词,那么就将其打散成多个可以识别的子词来编码成数字。
同样的,分词器也可以将用数字表示的句子重新转换回原有的句子。
|
|
2.3. 数据处理
为了方便后期使用,编写一个将编码后句子加上开始标记和结束标记。利用 tf.data.Dataset 的 map 功能来批量完成这一任务。首先需要定义一个函数:
|
|
显然这里我们使用了原生 Python 编写这个函数,这样的函数是不能为 map 所用的。我们需要使用 tf.py_function 将这个函数转换为计算图。(此函数可以将原生 Python 编写的计算过程转换为 Tensorflow 流程控制的计算图,详情请参考 py_function)
|
|
于是,我们可以给训练数据集和验证数据集中每个句子加上开始标记和结束标记:
|
|
为了能够让这个模型较小,我们只使用句子短于 40 个单词的句子来作为输入数据。这里利用 tf.data.Dataset 的 filter 过滤器功能来快速筛选出需要的数据。
为了使用 filter,首先要定义一个过滤器函数。这是一个布尔函数,如果一条数据符合要求,则返回真,否则返回假。显然,对于葡萄牙句子翻译至英文句子数据集,我们要筛选出所有成对相同意思的句子,并且两条句子都短于 40 个单词(编码后并加上了开始和终结标记后的长度)。
|
|
类似的,对数据集进行筛选:
|
|
我们已经知道, 输入给 Transformer 的句子通常不会单句地输入,而是把句子叠成一批输入。将一批有长有短的句子叠成一批,需要将较短的句子补 0 使其长度匹配当前一批中最长的句子。
|
|
显然,验证集合也需要进行类似的处理操作(验证操作无需随机)。
|
|
取出一个数据看一看:
|
|
3. 损失函数设计
损失函数的设计较为简单,需要考虑输出的句子和真正的目标句子是否为同一句子。只需要使用一个交叉熵函数。有一点需要注意,由上一章数据处理可以看出,数据中含有大量的填充(补0),这些填充不能作为真正的输入来考虑,因此在损失函数的计算中,需要将这些部分屏蔽掉。
|
|
同时,定义两个指标用于展示训练过程中的模型变化:
|
|
4. 优化器与学习率
Transformer 使用 Adam 优化器,其 $\beta_1$ 为 0.9, $\beta_2$ 为0.98, $\epsilon$ 为 $10^{-9}$。其学习率随着训练的进程变化:
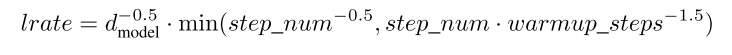
其中,这个 warmup_step 设定为 4000。如此设计,学习率随着训练(Train Step)的变化就如下图所示
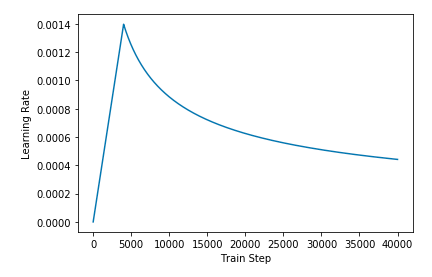
学习率的变化,我们通过继承 tf.keras.optimizers.schedules.LearningRateSchedule来实现。顾名思义,这个类会创建一个可序列化的学习率衰减(也可能增加)时间表:
|
|
优化器便可以方便地使用这个类的实例改变学习率优化。
|
|
5. 自回归原理
至今位置,我们已经拥有了 Transformer 的完整模型,数据输入和优化器。
但显然,Transformer 和 传统的 RNN 按时序依次读取输入和输出的训练方式“看起来”不同——它一次输入整个句子。而 encoder-decoder 架构是自回归的:通过上一步产生的符号和这一步的输入来预测这一步的输出。开始训练之前,需要了解 Transformer 是如何实现自回归的。
Tranformer 使用导师监督(teacher-forcing)法,即在预测过程中无论模型在当前时间步骤下预测出什么,teacher-forcing 方法都会将真实的输出传递到下一个时间步骤上。
当 transformer 预测每个词时,自注意力(self-attention)功能使它能够查看输入序列中前面的单词,从而更好地预测下一个单词。为了仅能让其查看输入序列中前面的单词,则需要前瞻遮挡来屏蔽后方的单词。
也就是说,若输入一个葡萄牙文句子,Tranformer 将第一次仅预测出英文句子的第一个单词,然后再次基础上依次预测第二个,第三个。
而训练过程也应该模拟这样的预测过程,每次仅增加一个目标序列的单词。
因此,我们将目标句子改写成两种:
原目标句子:sentence = “SOS A lion in the jungle is sleeping EOS”
改写为:
tar_inp = “SOS A lion in the jungle is sleeping”
tar_real = “A lion in the jungle is sleeping EOS”
(SOS 和 EOS 是开始标记和结束标记。)
真正输入给 Decoder 部分的是前者,配合前瞻遮挡它将模拟逐个单词产生的模型历史预测。而后者,则代表着模型当前步骤应该依次预测出的单词序列。很显然,他们应该仅仅只有一个单词的位移。
6. 训练
6.1. 超参数
Transformer 的基础模型使用的数值为:num_layers=6,d_model = 512,dff = 2048。
|
|
6.2. 训练
|
|
6.2.1. 创建遮挡
- 首先要对输入数据(原始句子和目标句子)创建填充遮挡(填充了 0 的位置标记为 1,其余部分标记为 0,这里与损失函数的部分刚好相反)。
- 对于编码器解码器结构,当编码器预测后方的单词,只使用前方已经预测出的单词。为了实现这一效果,需要使用前瞻遮挡。
无论哪种遮挡,0 标记着保留的部分,1 标记着要遮挡的部分。
|
|
6.2.2. 创建训练步骤及保存模型
为了保存模型,需要创建一个检查点管理器,在需要时使用此管理器来保存模型:
|
|
根据 5. 节的描述,将对目标序列进行调整和创建遮挡。最终实现训练过程。
在TF2.0中,由于使用了 eager excution 导致的性能下降,将使用@tf.function 装饰器将代码转换为传统的计算图提升性能。但这种转换并非完全智能,若没有良好的限制,则会因为输入 Tensor 的变化导致无法复用已有的计算图,导致冗余的转换。详情请参考Graph Execution 模式。
|
|
6.2.3. 开始训练
|
|
效果如下:
|
|
7. 评估
以下步骤用于评估:
- 用葡萄牙语分词器(tokenizer_pt)编码输入语句。此外,添加开始和结束标记,这样输入就与模型训练的内容相同。这是编码器输入。
- 解码器输入为 start token == tokenizer_en.vocab_size。
- 计算填充遮挡和前瞻遮挡。
- 解码器通过查看编码器输出和它自身的输出(自注意力)给出预测。
- 选择最后一个词并计算它的 argmax。将预测的词连接到解码器输入,然后传递给解码器。在这种方法中,解码器根据它预测的之前的词预测下一个。
评估函数:
|
|
可视化注意力:
|
|
单句子测试:
|
|
效果:
|
|