
从 0 开始学习 Transformer 番外:Transformer 如何穿梭时空?
1. 前言
讲解 Transfomer 在训练阶段为何无需循环调用模型即可完成导师监督(teacher-forcing)法。讲解前瞻遮挡原理的精妙用法:通过一次正向传播,模拟模型逐个得到得到整个目标句子的预测过程。
2. Transformer 穿越时空了?
首先,我们来看看 Transofrmer 是如何完成导师监督的(下面这是一张动图,依然来自Jay Alammar,有可能加载不出来,请参考原文The Decoder Side部分):
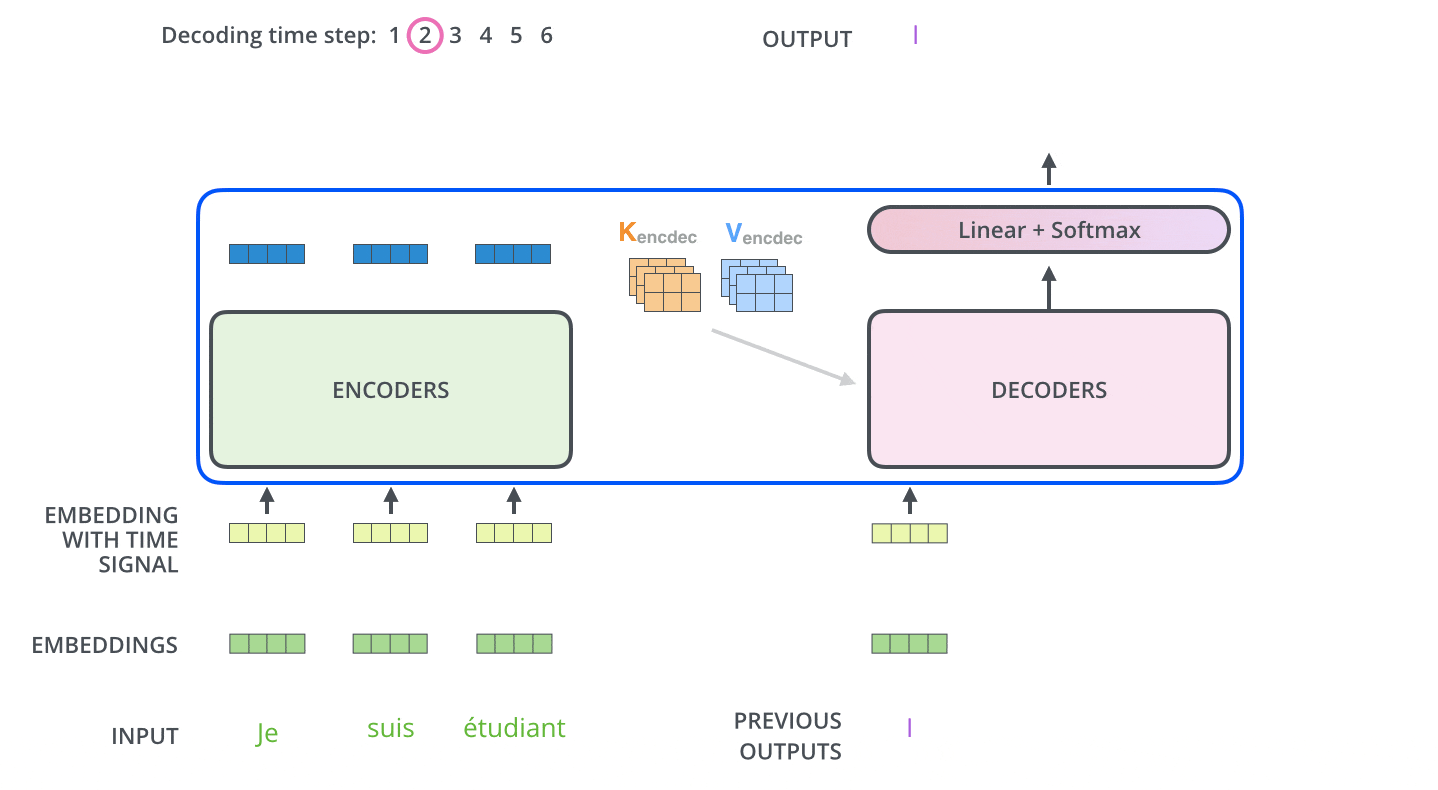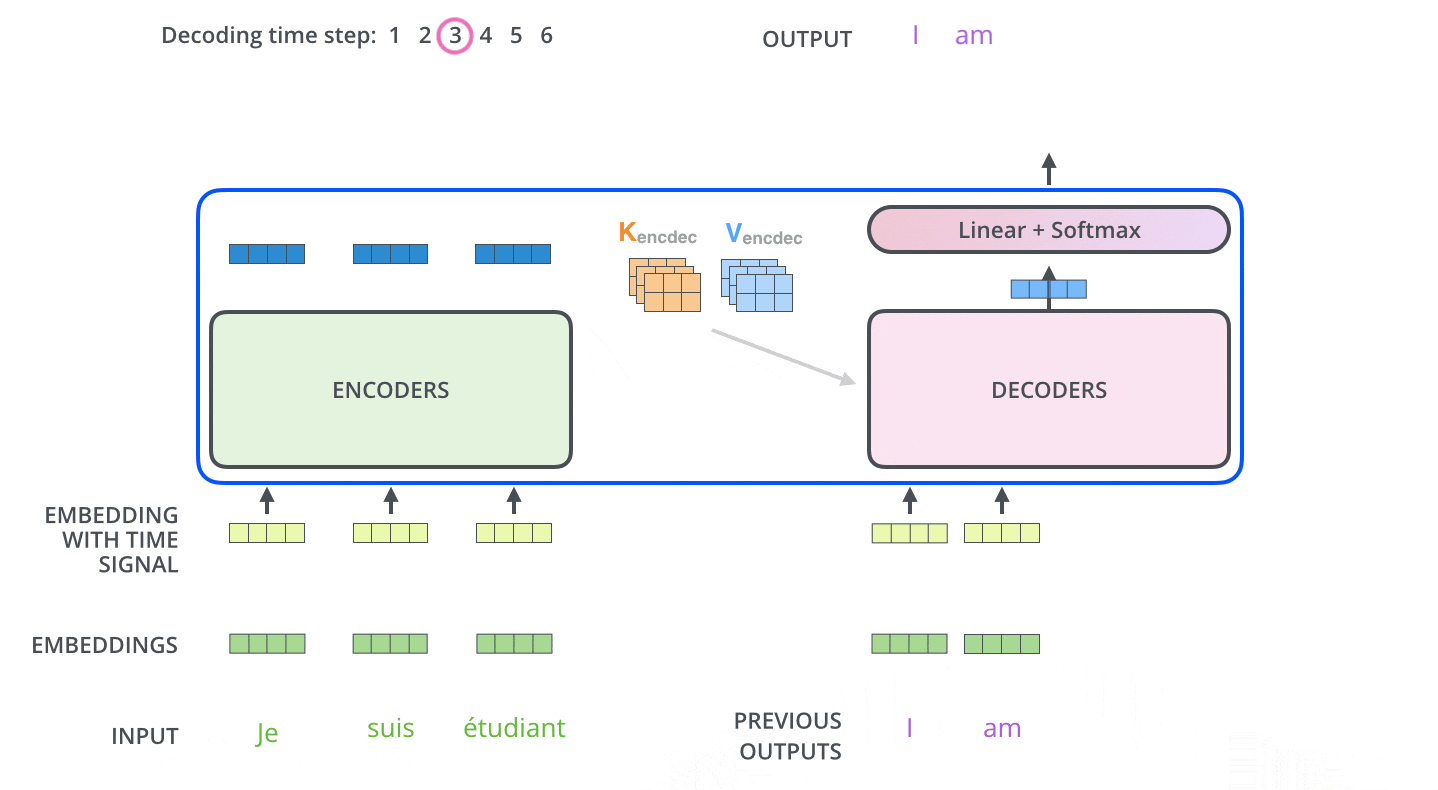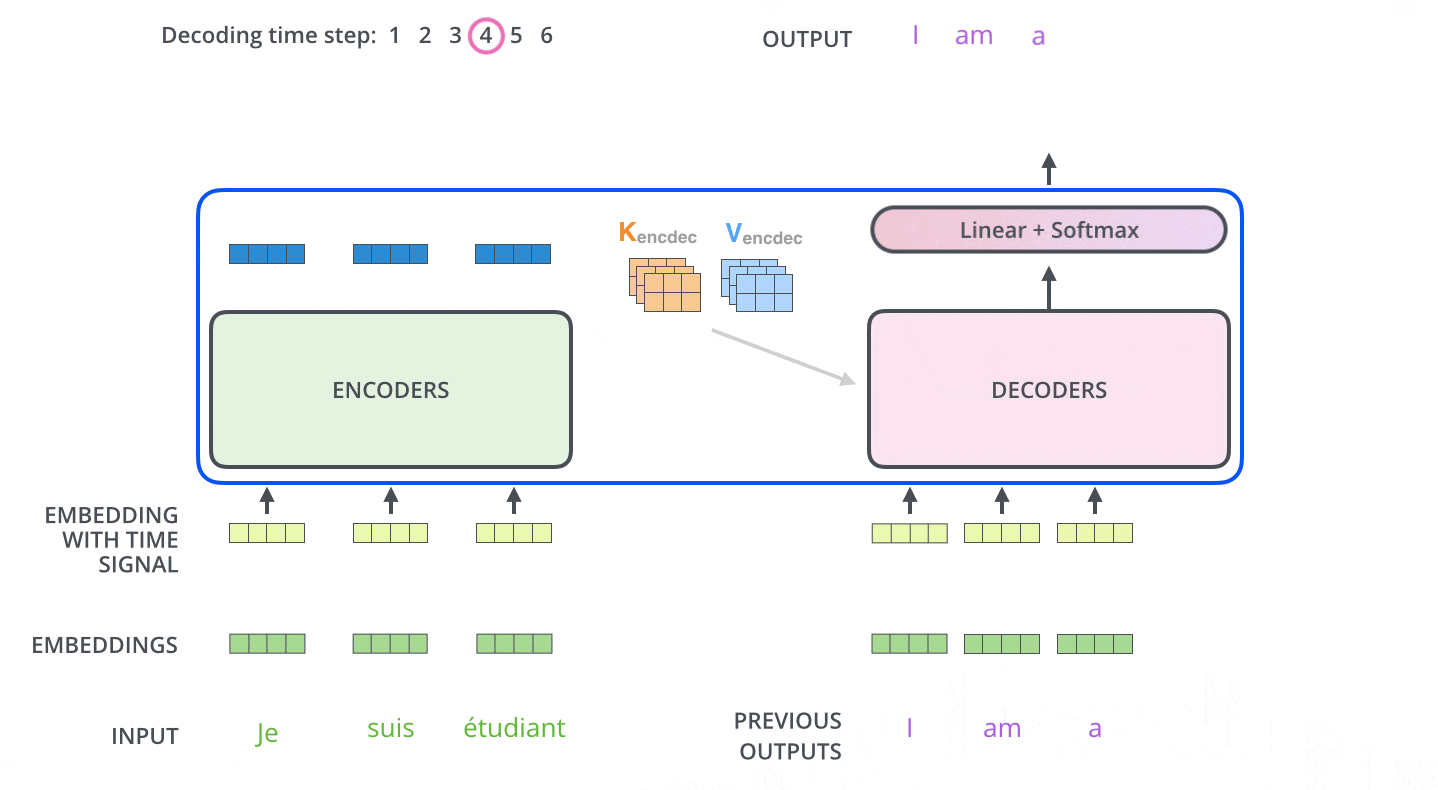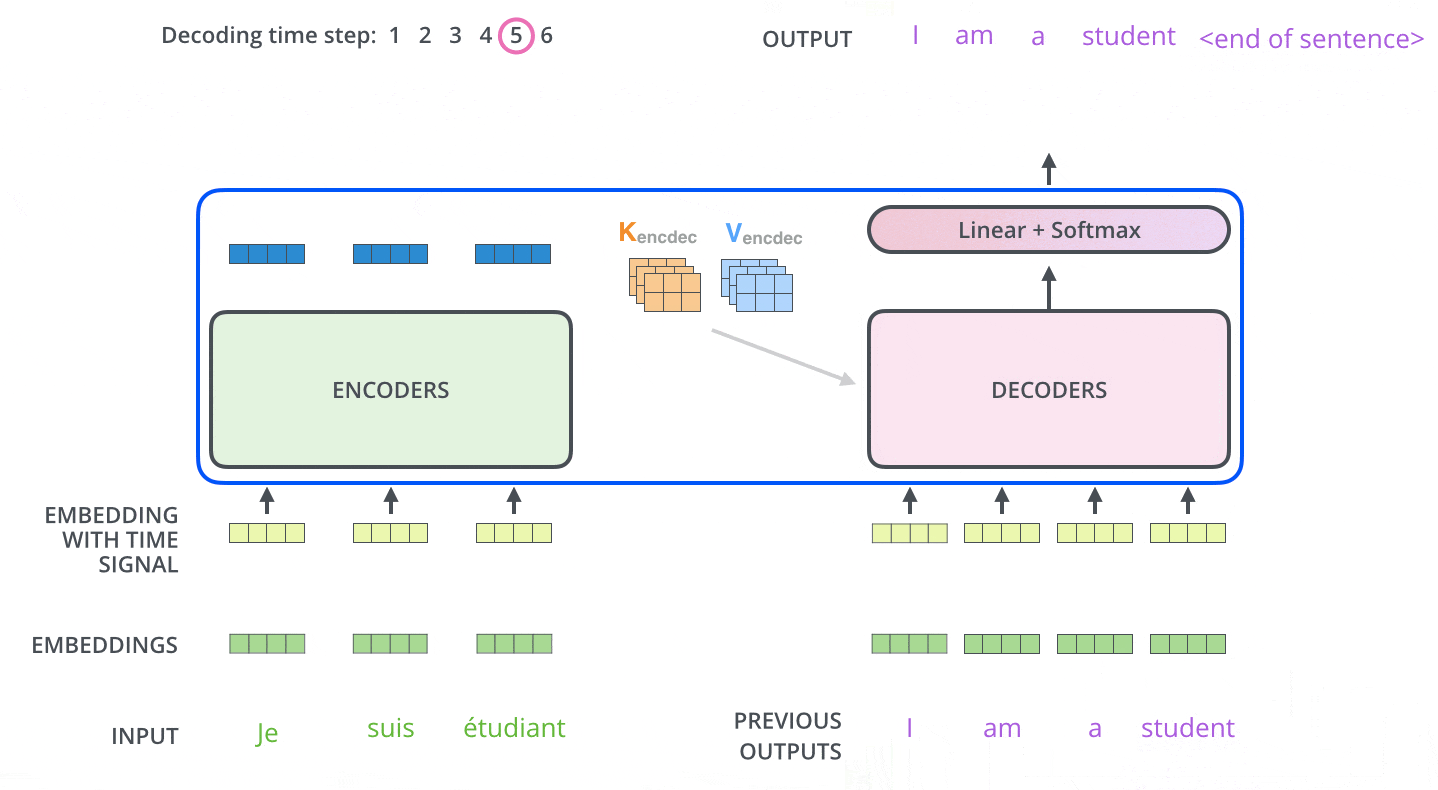
这和本系列第二篇文章的 7.评估 部分是一致的:
|
|
代码和动图过程一致。想要预测I am a student。首先我们将其处理成:<SOS> I am a student 作为解码器端的输入。而我们预期需要的得到的输出是 I am a student <EOS>。
显然,第一次传输给解码器端的输入,只是一个开始符号:
<SOS>
此时预测出的是第一个单词:
I
然后,将预测出的第一个单词结合原输入一起输入解码器端:
<SOS> I
得到新的输出:
I am
这时我们将最后一个单词 am 结合上一步输入一起输入解码器端:
<SOS> I am
得到新的输出:
<SOS> I am a
反复此过程,直到新的输出最后一个单词代表结束符号 <EOS>。返回上一步输出(上步输出不包含 <EOS>)。
显然,每一步预测都需要依赖上一步预测的结果。
而看过前两篇文章的聪明网友一定发现了,我们在训练过程中,并没有循环调用这个步骤,而是直接将整个句子输入给编码器端。
也就是说,训练过程并没有循环依赖前一次输出的步骤。
|
|
Transformer 是如何在训练阶段通过一次预测过程就完成了本应循环一个句子长度那么多次的预测过程呢?莫非 Transformer 穿越时空了吗?
3. 使用真值模拟输出配合前瞻遮挡
因为后续的计算,如残差、拆成多头、编码器解码器注意力、全连接网络等等,都不会改变前瞻遮挡对于原输入句子和输出句子的意义(不放心的同学可以结合代码追踪运行一下),所以将解码器端无伤大雅地简化为一个带有前瞻遮挡的自注意力机制。
假设我们已经预测出了 I am a,需要预测出 I am a Student
那么输入序列将是 <SOS> I am a。其表示为 (seq_len, depth) (因为只考虑一个句子和单头,所以省略了前置维度(batch, head_num))。
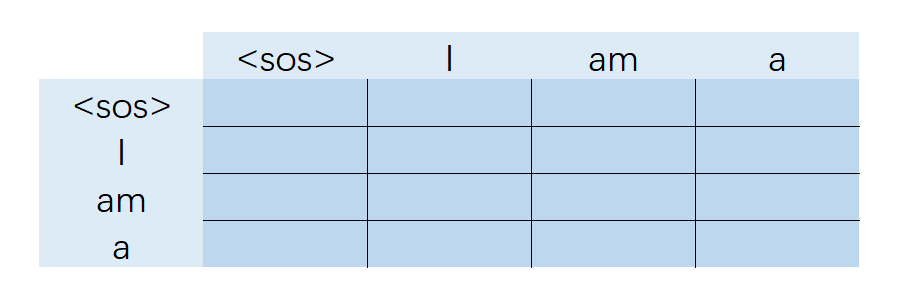
对于注意力机制,Key 和 Query 都是输入序列。显然,其自注意力权重(seq_len, seq_len)示意图如下:
而生成的前瞻遮挡(seq_len, seq_len)示意图如下:
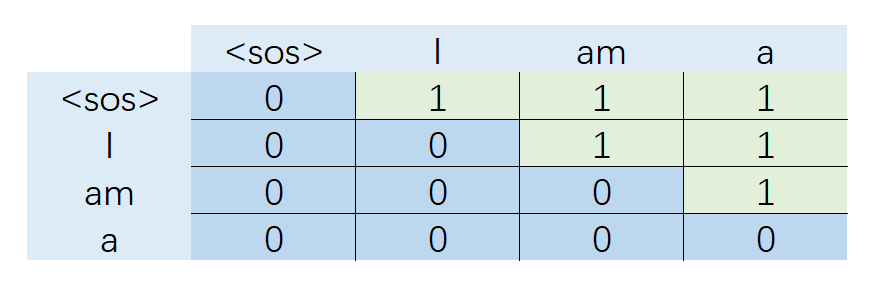
由于前瞻遮挡的存在,最终注意力权重将只留下左下标为 0 的深蓝色部分。
这样的注意力矩阵乘上和 <SOS> I am a 依次对应的 Value (seq_len, depth):
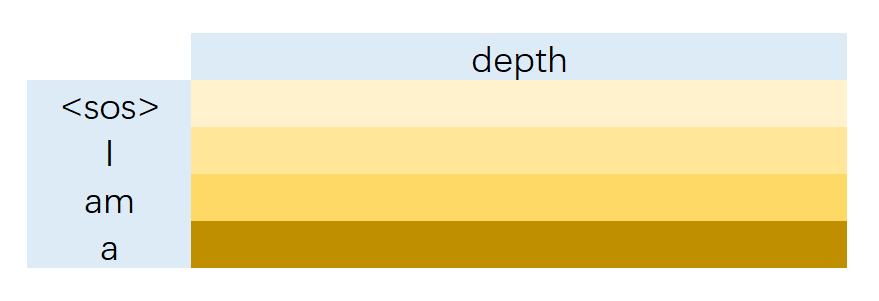
得到的结果(seq_len, depth),便应该是 I am a Student 的表示。
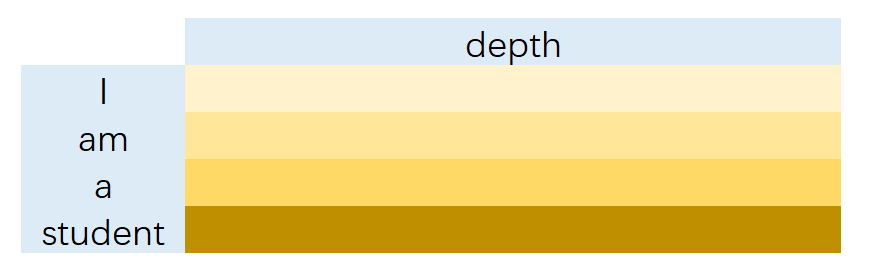
观察此乘法的过程(注意力权重点乘Value),由于前瞻遮挡的存在,这输出中的 I 实际上只来自 <SOS> 。而 am 则来自 <SOS> I 的加权求和。同样的, a 来自 <SOS> I am 的加权求和。
如此巧妙!不需要反复调用Tranformer,显然,由于前瞻遮挡,注意力权重求和的过程已经潜在地完成了每一步导师监督(teacher-forcing)法的过程。
在预测过程中,由于我们没有目标序列的真值,我们无法提前知道结束符号 EOS 前每一步的输出。但训练过程中,我们早已经拥有了 EOS 前所有的真值,将真值作为模型 “本应该” 的输出序列,再输入解码器层,前瞻遮挡将潜在地一次完成每一步导师监督(teacher-forcing)法的过程。